In this article, we are going to explore the different Ensemble Models and the Boosting Machine Learning Algorithm in detail.
You might have heard about boosting machine learning algorithms from your peers, friends, or family members, who are working in the industry of machine learning and data science.
In fact, you might have even used this algorithm before while solving problems or trying to develop your own models to predict the outcome of future data points in the business domain.
So, what is boosting a machine learning algorithm? And how can it be used to solve various tasks related to predictive analytics?
In this article, we will try to answer some of these questions and also discuss some of the different types of boosting algorithms used in machine learning today.
What is Boosting in Machine Learning?
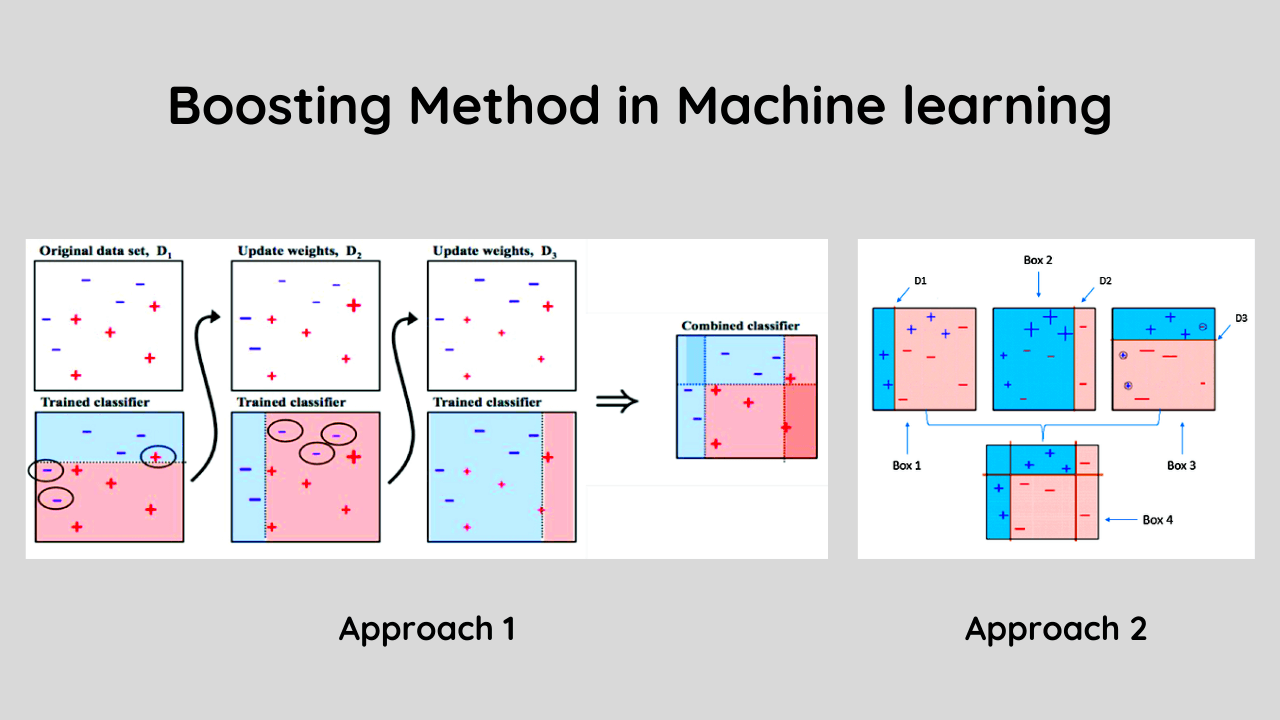
Boosting is an ensemble learning technique that combines many different weak learners to create a strong learner.
It works by iteratively combining a weighted sum of weak classifiers with similar performance on training data, in order to form a new classifier that is more accurate than each individual base learner.
In machine learning, boosting or boosting algorithm(s) can be used for both regression and classification problems.
When applied for classification, it is known as classification boosting; for regression, it is known as regression boosting.
Boosting was first introduced by Yoav Freund and Robert Schapire in 1997 (1), This seminal paper introduced AdaBoost, one of the most widely-used boosting algorithms for supervised learning today.
What are Popular Boosting (Ensemble) Algorithms?
The following are some of the most popular boosting algorithms:
- AdaBoost
- Gradient Boosted Decision Tree
- GBM
- XGBoost
- LightGBM
- CatBoost
- LogitBoost
- Random Forest Classifier
- ExtraTrees Classifier
- Stochastic Gradient Boosting
- Forward Stagewise
- Backward stagewise
How do Boosting Algorithms Work?
The underlying machine learning utilized for boosting algorithms can be anything, It can be a decision stamp, margin-maximizing classification algorithm, etc.
Before learning this boosting machine learning algorithm(s) first understand the concept of Ensemble learning or Models in it.
What are the Ensemble Models?
Suppose we have an ensemble model that consists of various boosting machines i.e. when combining multiple weak learners becomes more powerful than individual ones.
In general, there are 3 types of ensemble methods in machine learning -Boosting, Voting & Weighted Averaging.
In the case of the voting method, each weak learner should output predicted values as probability values instead of just predictions i.e., 1’s and 0’s only.
Then, the voting rule calculates these probabilities to find out a final decision/prediction/classification value.
There are many other ensemble methods that don’t necessarily involve all classifiers producing probabilistic outputs such as
- Bagging (bootstrap aggregating)
- Stacking (one-way active learning)
- Random forests
After taking a brief intro about ensemble methods, now comes the concept of boosting.
Related Article: What is a Supervised Learning? – Detail Explained
What are Decision Stamps?
Decision stamps are my favorite boosting machine learning algorithm. If you have taken a course on Machine Learning, then you have probably learned about boosting algorithms such as AdaBoost, Gradient Boosting, and XGBoost.
Decision Stamps use a slightly different approach from that of traditional boosting algorithms.
To understand how decision stamps work, let’s consider an example.
Suppose we have to build an e-commerce website to sell books where we want to estimate how many copies of each book will be sold in a week.
To do so, we decide to break down our users into two main groups: regular readers (80%) and casual readers (20%).
We gather all information about user purchasing history for one month which includes books that were purchased by regular readers in green and by casual readers in red.
We can easily see that most of the buyers are categorized under regular readers and only a few people buy books from the casual reader’s category.
Let’s suppose that we would like to predict how many sales can happen next week based on the last 1-month sales data.
One way is just trying several values (decision marks) to find out more precise answers but it is time-consuming especially when there are more variables involved.
What if we could somehow figure out what values these variables should take? It turns out that decision stamps can help us with exactly that! First, we need to choose some value to act as a stamp.
Then we start with a random guess (usually uniform distribution), then repeatedly update it using past results while adding small amounts of noise randomly sampled from Gaussian distribution at each iteration.
What is Margin Maximization Classification?
In machine learning and statistics, margin maximization is a classification strategy in which a classifier or class membership predictor attempts to maximize its margins by assigning predicted class labels and actual labels respectively to those training instances whose predicted classes and actual classes are closest.
The objective is to optimize both sensitivity (true positive rate) and specificity (false positive rate) simultaneously.
The boosting methods use boosting machines that employ popular decision-making models as their base learners on top of them.
Decision trees, linear models, logistic regression, neural networks, etc., can be used as base learners with some modifications to make them work as boosting machines for various tasks.
These ‘boosting’ methods have been successfully applied to various datasets for a variety of machine learning applications like classification, ranking, etc.
Related Article: What is Statistical Modeling? – Use, Types, Applications
What is Gradient Boosted Trees?
The goal of Gradient Boosted Trees is to fit a function to data and then use that function to make predictions on new data.
To do so, we need both
1. A way to define a function that maps inputs (X) into outputs (Y), and
2. An evaluation function that gives us back an idea of how good our model actually is at predicting output values from input values X.
This is known as a regression problem or classification problem depending on what you are trying to solve.
In GBM, we will be looking at the Regression problem: given a set of points in two dimensions, predict another point based on its x-y coordinate position relative to all other points.
How are Trees Useful for Regression?
Well, think about it like this if you have millions or even billions of data points to use for training your decision stump you can keep adding more decision rules so that it gets better over time with enough data points.
But there has to be some bound between how many layers of decision stumps should there be? That’s where trees come in handy because they give you a visual approach to defining these different levels.
Let’s go through each case: How would one arrive at these functions? In XGBoost for example, we use only two parameters:
1. λ is a weight or penalty term that affects how much emphasis is given to samples with a low probability of being positive.
This is commonly known as regularization and it helps in preventing overfitting.
2. max_depth is similar to decision stump where you don’t want your function to have too many levels of logic (such as if/else).
You will then need some kind of learning algorithm such as Gradient Boosted Trees which can help you construct a model tree through iterative improvements while providing some assurance on maintaining performance stability.
Types of Boosting Algorithms
- AdaBoost (Adaptive Boosting)
- Gradient Tree Boosting
- XGBoost
- PSO (Particle Swarm Optimization)
- DE (Decision Forest)
- Bagging
- Random Forest
- Hierarchical Boosting
- Adaboost
- LogitBoost
- RANSAC (Random Sample Consensus)
- Elastic-Net
- Stochastic Boosting
- GBDT (Gradient Boosted Decision Trees)
- SMOTE (Synthetic Minority Over-sampling Technique) etc.
Boosting Algorithm: AdaBoost
AdaBoost, often known as adaptive boosting or soft boosting, is a type of machine learning algorithm used for ranking and classification, AdaBoost was invented by Yoav Freund and Robert Schapire at IBM in 1997.
The idea behind it is simple: given a set of training examples, find a weighted combination of these examples that classifies new examples in an optimal way, This weighting can be updated iteratively using some measure of error rate.
It’s worth noting here that although there are many boosting algorithms (Adaboost being just one), they are all commonly grouped together under the boosting umbrella term.
There are many variations on boosting methods to achieve similar results; XGBoost is one such example we will cover shortly.
Boosting Algorithm: Gradient Boosting
Gradient boosting is a powerful family of machine learning algorithms for performing gradient descent on decision trees.
Gradient boosting machines (GBMs) was developed by Jerome Friedman, Trevor Hastie, and Rob Tibshirani in 2001.
Gradient boosting machines are a powerful tool for solving a wide range of supervised learning problems.
The algorithm constructs successive decision trees to fit one training example at a time. As it fits each new example it updates its understanding of which features are important to predicting future examples.
To train each tree, GBM uses an estimation procedure called gradient descent based on stochastic optimization.
It starts with an initial estimate for model parameters and iteratively improves these estimates until a desired level of accuracy has been reached or some other stopping criterion has been met.
Here’s how boosting works, You start off with a weak classifier that’s barely better than random guessing.
Then you combine that classifier with every feature subset you can think of and use them to train another classifier.
At each step, you do something clever that lets you take advantage of information from previous steps in order to make your classifiers more accurate.
Boosting Algorithm: XGBoost
XGBoost is an implementation of gradient boosting, a machine learning technique for regression and classification problems, which has recently gained popularity because of its strong performance.
Originally implemented in C++ as part of the Hadoop ecosystem, XGBoost is now also available for Python and R.
For big data problems, XGBoost often performs better than other classical machine learning techniques such as random forest or support vector machines (SVMs).
What Makes XGBoost so Powerful?
How does it work under the hood? And what are some best practices to use when applying XGBoost to real-world problems?
But first, you should know how XGBoost works and why it can help you tackle complex machine learning problems with little effort.
While learning boosting you need to focus on XGBoost’s internal workings, explain how we can utilize parallel processing capabilities built into modern CPUs to accelerate computation speed.
Also, you need to learn the differences between regularized optimization algorithms used by XGBoost vs. random forests and how you can apply XGBoost effectively.
To Summarize XGBoost with several interesting applications that demonstrate how easily one can incorporate high-performance boosting into existing applications via public APIs provided by XGBoost.
This means that boosting code written using XGBoost can be distributed just like any other open-source software.
This ability to seamlessly integrate boosting with your application enables new opportunities across many fields, especially financial services where high demand for cutting-edge technology is driven by competitive advantage.
Conclusion
The aim of the post is to have a clear view of boosting machine learning algorithms like AdaBoost, Gradient Tree Boosting, XGBoost, and others.
Read more to know about how they work and which one is right for you based on your data set requirements.

DataScience Team is a group of Data Scientists working as IT professionals who add value to analayticslearn.com as an Author. This team is a group of good technical writers who writes on several types of data science tools and technology to build a more skillful community for learners.