

In this article, we are going to explore what are the different forms of data lakes and what is the exact meaning of data lakes in the software and data industry.
Before getting a deep understanding of different forms and the usability of Data Lake first understand why we need to know about Data Lake and why it is really significant in today’s date.
Data is getting king in each and every industry and every aspect of life because everything is getting digitized and online usage of transactions is exponentially increasing day by day.
Similarly, there is a large amount of data gathering, processing, and storing practices that are getting more evolve and various types of tools and technologies and handling those aspects.
We are going to focus on the storage part of data here because data lake is the data storage and management tool or technology in the market which have a peculiar way to handle several types of data.
There are other data storing and management technologies are available but each and every tool and technology has its own pros and cons, however different functionalities.
That’s the reason understanding the data lake and its different forms can help you to solve several types of data problems and increase the chances get an expert in data-related solutions.
What is Data lake meaning?

A Data lake is a storehouse of the different types of information put away in its normal configuration, ordinarily as masses or documents.
A data lake is a brought-together chronicle that grants you to store all your coordinated and unstructured data at any scale.
You can store your data without any assurances, without having to at first construct the data, and run different sorts of assessment from dashboards and insights to enormous data taking care of, persistent examination, and AI to coordinate better decisions.
What is data lake architecture?
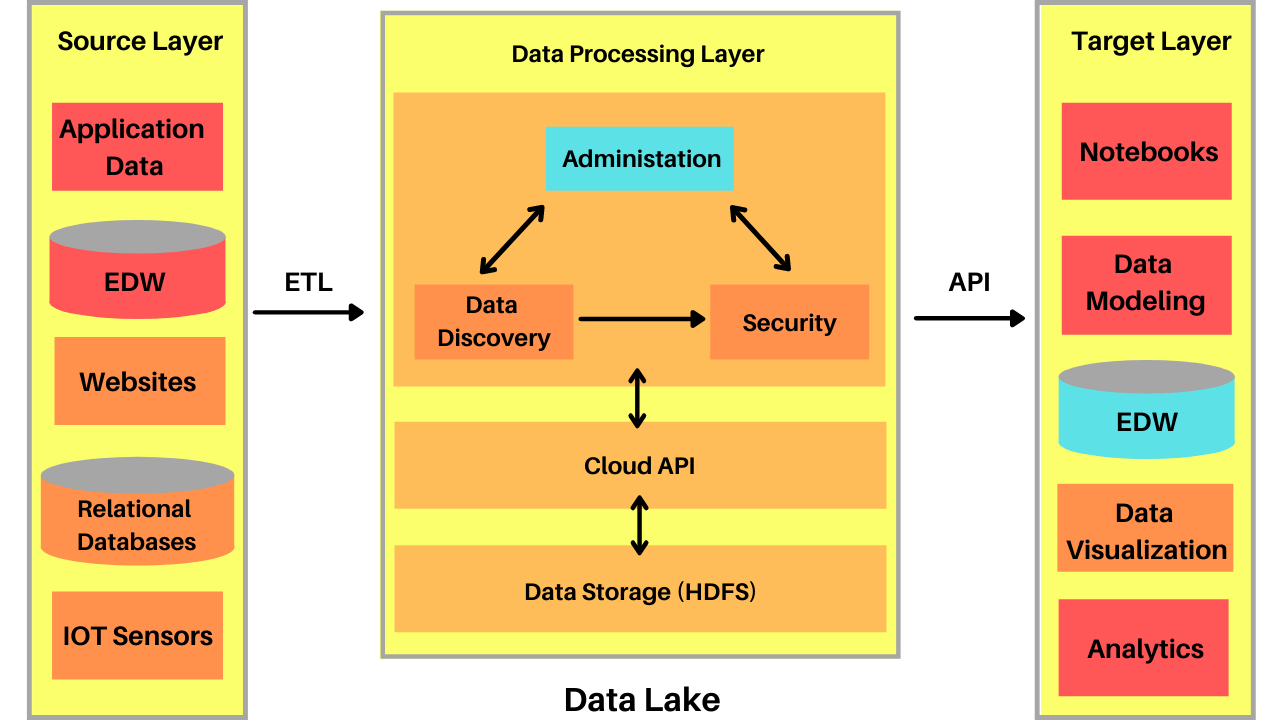
All substances will be ingested into the Data lake or arranging storehouse and afterward looked at (utilizing a web search tool, like Cloudera Search or Elasticsearch). Where vital, the content will be dissected and results will be taken care of back to clients through search to a huge number of UIs across different stages.
Allow us to get what involves a Data lake by talking about the Data lake design. The accompanying chart addresses a significant level of Data lake engineering with standard terminologies.
data lake vs data warehouse

Data lake vs Datamart
A Datamart is a subset of an information stockroom. The objective is to have all the data identified with one subject in one spot. This makes it simple for end clients to utilize the information and permits them to deal with a little subset, consequently restricting the assets utilized.
Moreover, this improves security as you’re uncovering as little data on a case-by-case basis for every particular use case.
While a Data Wearhouse is multi-reason stockpiling for various use cases, an information store is a subsection of the information stockroom, planned and constructed explicitly for a specific office/business work.
Datamart contains different benefits for data management including Isolated Performance of data and Isolated Security of data.
it is divided into three main types like Dependent Data Marts, Independent Data Marts, and Hybrid Data Marts for isolated specific data management.
Data lake in hadoop

Hadoop is a significant component of the design that is utilized to fabricate information lakes. A Hadoop information lake is one that has been based on a stage comprised of Hadoop groups.
Hadoop is especially well known in information lake engineering as it is open source (as a component of the Apache Software Foundation project). This implies that it can fundamentally lessen the expenses of building enormous scope information stores.
While the Data lake idea can be applied all the more extensively to incorporate different kinds of frameworks, it most every now and again includes putting away information in the Hadoop Distributed File System (HDFS) across a bunch of grouped figures hubs dependent on product worker equipment.
The dependence on HDFS has, over the long haul, been enhanced with information stores utilizing object stockpiling innovation, yet non-HDFS Hadoop environment segments normally are essential for the undertaking Data lake execution.
The substance of a Hadoop Data lake need not be promptly consolidated into a conventional data set mapping or reliable data structure, which permits clients to store raw information with no guarantees; data can then either be broken down in its raw structure or ready for explicit examination utilizes on a case by case basis.
Data lake in aws

Conveying Data Lakes in the cloud
Data Lakes are an optimal responsibility to be deployed in the cloud, in light of the fact that the cloud gives execution, versatility, unwavering quality, accessibility, a different arrangement of logical motors, and gigantic economies of scale.
ESG research found 39% of respondents considering the cloud as their essential organization for investigation, 41% for information stockrooms, and 43% for Spark.
The top reasons clients saw the cloud as a benefit for Data Lakes are better security, quicker an ideal opportunity to sending, better accessibility, more successive element/usefulness refreshes, greater flexibility, more geographic inclusion, and expenses connected to genuine use.
Assemble your Data Lakes in the cloud on AWS
AWS gives the most secure, versatile, far-reaching, and financially savvy arrangement of administrations that empower clients to assemble their Data lake in the cloud, examine every one of their information, including information from IoT gadgets with an assortment of logical methodologies including AI.
Thus, there are more associations running their Data lakes and examination on AWS than elsewhere with clients like NETFLIX, Zillow, NASDAQ, Yelp, iRobot, and FINRA confiding in AWS to maintain their business basic investigation responsibilities.
Data Lake in Google Cloud

Google Cloud’s Data lake controls any examination of a piece of information that engages your groups to safely and cost-successfully ingest, store, and investigate enormous volumes of assorted, full-devotion information.
Since we’ve sorted out the contrast between information stockpiling and a data lake, we need to pick the best variation. There are numerous data lake arrangements available, yet for showcasing, there’s only one most ideal choice — Google BigQuery. How about we momentarily depict what Google BigQuery is and why it’s the best answer for putting away advertising information.
It’s hard to envision an advertiser who doesn’t work with Google Ads, Google Analytics, YouTube, and other Google administrations. Google is a genuine beast of promoting and publicizing. Furthermore, Google BigQuery is essential for Google’s foundation, In straightforward words, this implies local reconciliations.
Google is constantly fostering its cloud administrations stage, including BigQuery. So you don’t have to stress that this assistance will be deserted and stop to be upheld and refreshed.
Among its different benefits, Google BigQuery is straightforward and quick, and countless experts can work with it. It additionally accompanies instant arrangements of SQL questions so you can get valuable bits of knowledge from your gathered information.
Data lake in azure

Azure Data Lake Storage is an extensive, profoundly versatile, and cost‑effective Data lake answer for large information investigation based on Azure.
Azure Data Lake Storage consolidates the force of an elite record framework with a gigantic stockpiling stage to assist you with rapidly distinguishing bits of knowledge in your information.
It sorts out the put-away information into a pecking order of registries and subdirectories, similar to a record framework, considering a simpler route.
Therefore, information handling requires fewer computational assets, which, thus, lessens both the time and afterward the expense.
Purplish blue Blob Storage empowers you to store a lot of unstructured information in a solitary pecking order, otherwise called the level namespace, and can be gotten to utilizing HTTP or HTTPS.
Data lake storage gen2
Azure Data Lake Storage Gen2 expands on Azure Blob Storage abilities to upgrade it explicitly for scientific jobs.
A vital advantage of Azure Data Lake Storage Gen2 is that you can regard the information as though it was a Hadoop Distributed File System.
This component empowers you to store the information in one spot and access it through a wide scope of figure innovations, including Azure Databricks, HDInsight, and SQL Data Warehouse.
Data Lake Storage Gen 2 backings access control records and POSIX consent. You can set a granular degree of consent at the catalog or document level for information put away inside the information lake.
Various leveled namespace sorts out mass information into registries and stores metadata about every index and afterward the documents inside it.
Azure Data Lake Storage Gen2 assumes a crucial part in the entire scope of Azure information structures.
Conclusion
The prep and train stage distinguishes the advances that are utilized to perform, get ready, and model preparing and afterward scoring for Data science solutions.
The normal advancements that are utilized in this stage are Azure Databricks, Azure HDInsight, or Azure Machine Learning administrations.
At long last, the model and serve stage includes the advances that will introduce the information to clients.
These can incorporate perception instruments, for example, Power BI or information stores like Azure Synapse Analytics, Azure Cosmos DB, Azure SQL Database, or Azure Analysis Services. Frequently, a mix of these advances will be utilized, contingent upon the business prerequisites.
All types of data lakes are implemented and utilized for large-scale and complex types of data gathering and processing operations for high scale data storage.
Recommended Articles:
What Is Databricks? – Components, Features, Architecture
What Is Big Data? In Modern World
Apache Spark Architecture – Detail Explained
Data Warehouse Concepts In Modern World

Meet our Analytics Team, a dynamic group dedicated to crafting valuable content in the realms of Data Science, analytics, and AI. Comprising skilled data scientists and analysts, this team is a blend of full-time professionals and part-time contributors. Together, they synergize their expertise to deliver insightful and relevant material, aiming to enhance your understanding of the ever-evolving fields of data and analytics. Join us on a journey of discovery as we delve into the world of data-driven insights with our diverse and talented Analytics Team.








