

The architecture of Hadoop in big data is the crucial huge data handling software system, with massive data storage and execution engine.
The Hadoop framework presents the distributed data processing software environments over multiplied clusters of workstations using a modest programming model.
It is a software library designed to scale-up unique servers to thousands of separate common systems and every individual system enables local computation and storage.
Instead of depending on hardware to perform high availability, the library itself is invented to discover and manage failures at the application layer.
It is giving a profoundly accessible service on top of a cluster of computers, if anyone gets suspended others can handle the operation easily.
The Architecture of Hadoop In Detail.
The Hadoop system uses the architecture of Hadoop and associated applications systems to deliver distinct types of data manipulation and analytics on large data.
The Ecosystems of Hadoop are competent to query and process an immense amount of data like petabytes of large-scale data execution in few seconds.
The Hadoop system includes two divisions one is the Core mechanism for storage, processing and the second is the ecosystem components for a variety of operations.
The Detail Core Mechanism for Hadoop Architecture are as follows:

1. HDFS (Hadoop Distributed File System)
HDFS stands for the distributed file system which is the collection of files that operates a large quantity of data that runs on the cluster and the commodity hardware.
It is one of the primary components of Apache Hadoop which used to scale a single Hadoop cluster to thousands of data nodes.
2. YARN (Yet Another Resource Negotiator)
It is employed for commanding a diversity of tasks for big data same as scheduling the execution and allotting the resources to data for processing.
It uses an application manager for monitoring the data, execution activities, and a load of huge data.
3. MapReduce
It is one of the best data processing and execution mechanisms found in Hadoop for large-scale data management.
Hadoop MapReduce architecture is used to split the input data then map the keys to all data letters on shuffle and sort the data, at last, reduce the data by removing the duplication.
Hadoop Ecosystem Platforms and Mechanism are as follows:
Apache Hive
Hive is an apache open-source data warehousing software system use for reading, writing, and managing large amounts of data.
It supports Hadoop HDFS or Apache HBase for exaction of files for transformation and loading same as the ETL for analysis.
Apache Pig
Pig is a scripting language called Pig Latin that is used In the Hadoop system for ETL and analysis.
It allows data experts to write and execute complex data operations on data without knowing Java and helps programmers with simple scripting languages and SQL.
Apache Hbase
It is used for real-time read and writes operations on Big Data and it hosts very large tables of the database on different clusters of a data node in Hadoop.
HBase, look like document base data which means non-relational database form works on HDFS and Hadoop.
It works similarly to the google database technology called Bigtable database that is used for the file system of google.
Apache Spark
Spark is a 100 times faster and general processing engine compatible that works on top of Hadoop.
It can execute data in Hadoop clusters using the YARN execution engine or it can use its own execution mode for a variety of data in HDFS, HBase, Cassandra, etc.
Hadoop Setup Modes
Hadoop Architecture can be used in three different modes Standalone, Pseudo Distributed, Fully Distributed Mode to set up for your required form of applications and systems.
1. Standalone Mode
It is a Single node setup that required only one system and hardware which is default and non-distributed in nature.
In this mode setup Hadoop works as a single Java process, it requires a Java environment like JDK, JRE, etc. for execution.
2. Pseudo Distributed Mode
In this mode setup, the first step expected to configure the SSH for easily accessing and managing the separate nodes.
In this mode, it is significant to available the SSH configuration access to the multiple nodes for secure and fastest execution.
The few steps like configuration, enabling, and accessing of SSH are done, you can start configuring the Hadoop.
In this mode for one HDFS, it used one HDFS, one Name Node (NN), one Data Node (DN), and one Secondary Name Node (SNN).
For YARN it used one YARN, One Resource Manager (RM), and one Node Manager (NM).
3. Fully Distributed Mode
Fully Distributed Mode needs pseudo-distributed mode to perform, so before you start the distributed mode setup, you need to assure the setup of pseudo-distributed mode has done.
After setting up pseudo-distributed mode, then the second one is you need a minimum of two machines to set up a master for one and the slave for the second machine.
Hadoop daemons are distributed among many nodes that do data replication for fault tolerance typical for the production environment.
This fully distributed mode utilizes multimode activities and a tremendous amount of commodity hardware for fully distributed data execution and processing operations.
The Difference of Hadoop 1.x Vs Hadoop 2.x Version.
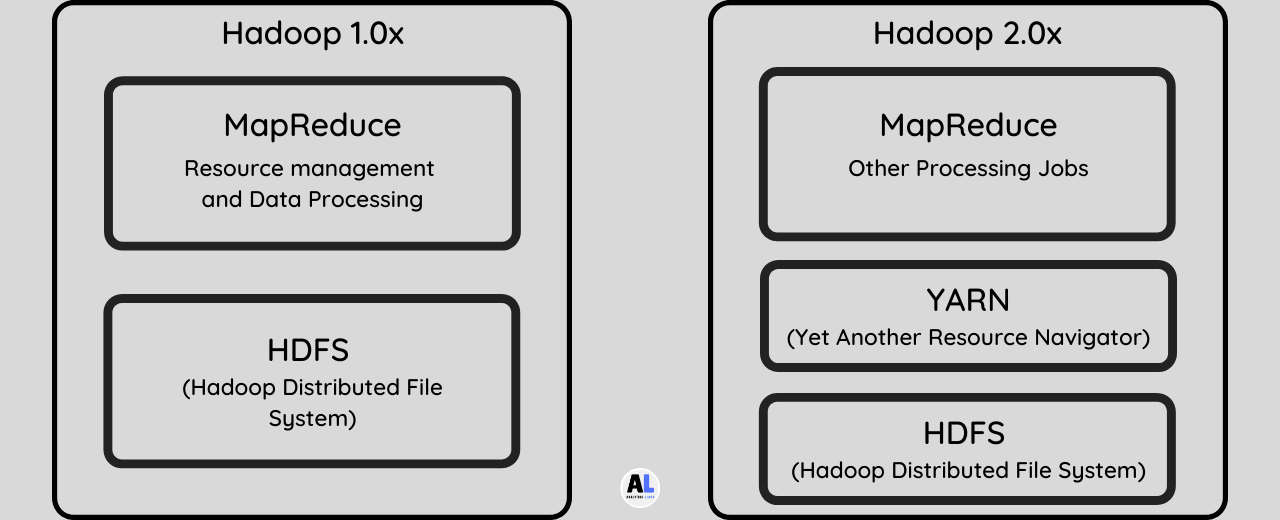
What is the Hadoop Architecture 1.x?
It is the first form of Hadoop Architecture which contains a few limitations and drawbacks for big data processing and scaling, it supports data Scalability of 4000+ nodes.
In Hadoop Job Tracker use to perform multiple activities like Job Scheduling, Resource Management, Job Monitoring, Re-scheduling Jobs, etc.
This shows that Job Tracker works in an overburdened for doing Scheduling and Monitoring the activities.
It has No High Availability on masters like name node (NN) and job Tracker (JT) which means that It supports only one Name Node (NN) and One Namespace per Cluster.
It follows the fixed slots for task execution means It runs only Map and Reduce jobs at the exact same time.
What is Hadoop Architecture 2.x?
It is the advanced form of Hadoop Architecture system which provides Hight availability and scalability which support the Scalability of 25000+ nodes.
Hadoop 2.x is used for High Availability on master’s nodes like name node and resource manager (Ex. NN, RM) can be setup
Resource Manager is used for scheduling the task when Application Master is used for monitoring the actives which reduces the high load.
It contains the Hight size of dynamic and flexible Containers to store and handle huge data.
Conclusion
Hadoop is the revolution in big data technologies for handling high population data and it is very crucial for huge business transactions.
It reduces the use of traditional systems and old data management applications and combined the various domain data execution together.
Recommended Articles:
What Is Big Data? In Modern World
Apache Spark Architecture – Detail Explained
Data Warehouse Concepts In Modern World

Meet our Analytics Team, a dynamic group dedicated to crafting valuable content in the realms of Data Science, analytics, and AI. Comprising skilled data scientists and analysts, this team is a blend of full-time professionals and part-time contributors. Together, they synergize their expertise to deliver insightful and relevant material, aiming to enhance your understanding of the ever-evolving fields of data and analytics. Join us on a journey of discovery as we delve into the world of data-driven insights with our diverse and talented Analytics Team.