

A tremendous amount of information has been producing every single day and Spark Architecture is the most optimal solution for big data execution.
There is a system called Hadoop which is design to handle the huge data called big data for today’s very highly transactional world.
Executing a huge amount of data is not an easy task that’s why MapReduce use for data execution in the Hadoop system.
Still, map-reduce have some limitation and its uses in the Hadoop system, and may or may not work for a variety of structure and unstructured data.
The fastest execution engine requires various forms of data that’s why spark comes into the picture, which is much faster and reliable than Hadoop MapReduce.
What is Apache Spark?
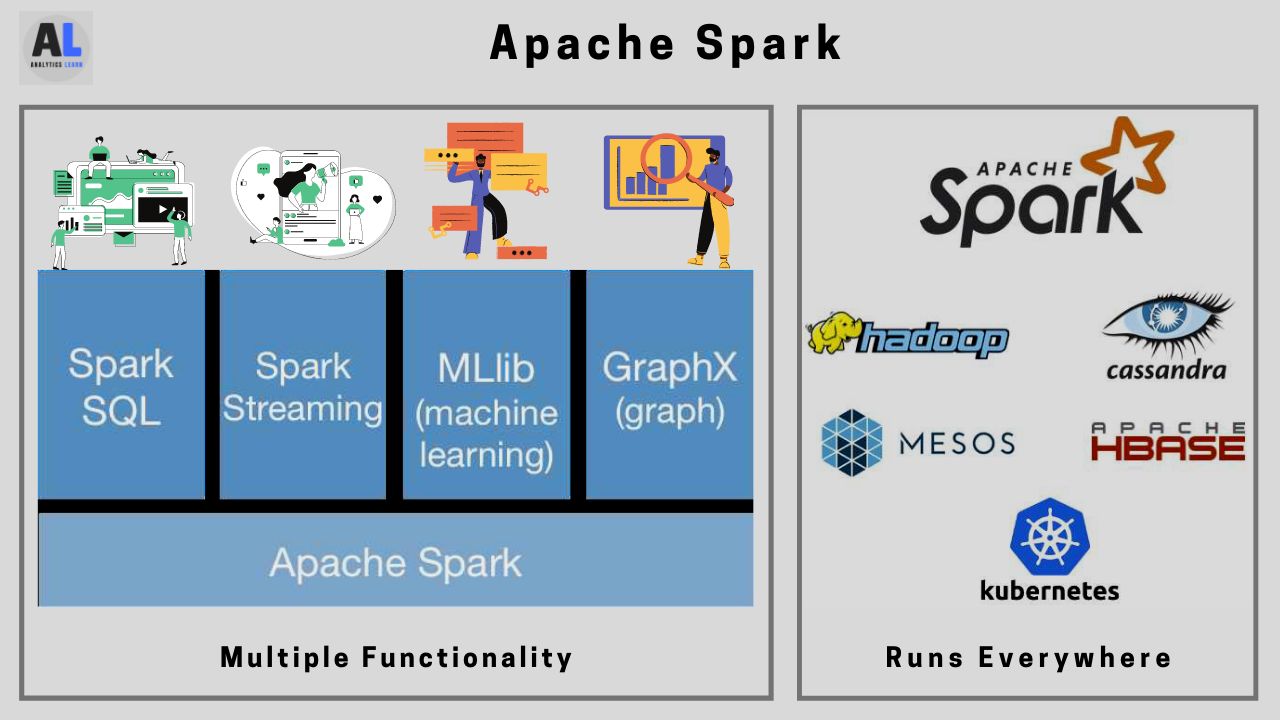
Apache spark is the General-purpose data execution engine that can work on a variety of big data platforms like Hadoop.
It provides multiple stacks of libraries for various data-related and analytics operations.
Spark supports the databases/SQL queries with the help of SQL and DataFrames procedures for structured and semi-structured data using SQL queries.
You can implement the ML-Lib module functionality of spark for machine learning and for predictive modeling.
Same like other functionality the GraphX module in spark used for graph processing and visualization of data.
Spark Streaming in spark used for building and handling streaming data application and stock market data analysis.
What is the Spark Architecture?

Spark architecture is based on three important parts for data execution those are cluster manager, spark context, worker nodes.
Every single application occupies its own executor processes and runs tasks in multiple threads at the time of the application execution.
The node which carries the spark context object name as a master node, the interactive shell or code works as a driver program that handles your application.
In spark code, the Spark Context gets created which gives access to all the Spark functionalities. whatever you want to execute in code the Spark goes through Spark context.
The Spark context and cluster manager work together to handle various complex jobs and the driver program and Spark context used for job execution in the cluster.
The job in spark gets divided into multiple tasks that can be distributed over the different worker nodes and created RDD can distribute to nodes and store in the cache.
The Worker nodes in spark work as slave nodes to execute the multiple tasks on the partitioned RDDs and result in the Spark Context.
The Spark Context is addressed by the network from the worker nodes which run on the same Local Network.
The Spark Context is working to monitor and receive the incoming connections from the executors during their lifetime.
What is RDD?
In spark, RDD Abbreviated as “Resilient Distributed Dataset” which works as a Fundamental data structure uses for creating and defining data objects.
RDD is the Immutable collection of objects which means it is read-only (not changeable) in spark.
Each RDD can partition and distribute over different nodes without the fault-tolerant and partitioned collection of records and that’s how it works in Spark.
How to Create an RDD?
RDDs in spark can create using following different ways like
- Taking the Reference of the dataset from distributed storage like HDFS, Hbase, Cassandra, etc.
- Parallelizing an existing collection of data using the parallelize() function in pyspark.
- The other you can try for creating RDDs using transforming other RDDs objects.
What are the RDD Operations?
RDDs in spark support two types of operations for data handling and execution are Transformations and Actions.
RDD Transformations
It is used to create a new dataset from the existing one like simple steps to calculate the data execution steps.
All transformations in Spark use lazy evaluation which calls it lineage (dependency graph) in spark.
The transformed RDD computes every time when you run the action on it and it perseveres on disk space.
RDD Actions
The Actions execute the RDD values after running a computation on the dataset and it reduces the execution time.
The RDD action aggregates all the elements of RDD Transformations and returns the final result to the driver program.
Conclusion
Apache spark architecture is the very powerful data execution engine provide by apache open-source licensed and data bricks provides all the system failure supports.
Spark is working on Hadoop architecture or standalone that makes it more reliable and popular for the fastest data performance engine for big data analytics.
Recommended Articles:
What Is The Process Of Big Data Management?
What Is The Architecture Of Hadoop?
Data Warehouse Concepts In Modern World

Meet our Analytics Team, a dynamic group dedicated to crafting valuable content in the realms of Data Science, analytics, and AI. Comprising skilled data scientists and analysts, this team is a blend of full-time professionals and part-time contributors. Together, they synergize their expertise to deliver insightful and relevant material, aiming to enhance your understanding of the ever-evolving fields of data and analytics. Join us on a journey of discovery as we delve into the world of data-driven insights with our diverse and talented Analytics Team.
