

Here we are going to learn the complete architecture of Databricks with spark including each layer and component of the architecture.
The architecture of Databricks is categorized into three significant layers, the first one is Cloud Service, the second one is the Runtime layers, and the last is Workspace.
Before getting direct to Databricks with spark architecture first deep dive into each layer of Databricks and understand their components one by one with their usage.
Important Layers of Databricks with Spark Architecture
Databricks has multiple layers of abstraction but here we are going to focus on three main layers those are cover all the modules and services on Databricks.
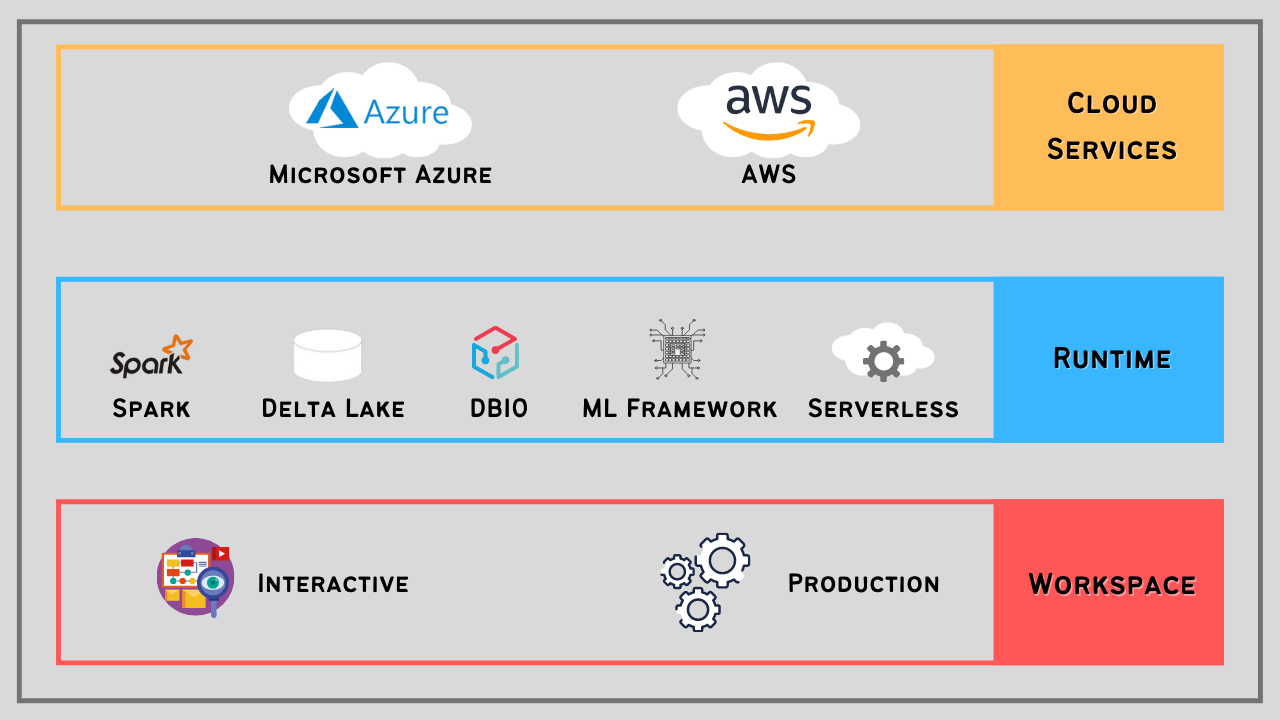
1. Cloud Service.
Databricks are available on This Top-level cloud platform including Microsoft Azure and Amazon Web Services and Google cloud.
You may have an idea about virtual machines or VM, implementing and running the VM in the cloud is easy in today’s world.
Whereas Databricks mostly runs on the cloud system, which provides VMs or nodes of a cluster after selecting config and it enables to launch of multiple clusters at a time.
That helps you to work with different clusters that contain multiple configurations, and those mostly come preinstalled when you create it in Databricks Runtime.
Databricks File system on Cloud
We will talk about Runtime in just a minute and one of the great features of Databricks is the native support of a distributed file system.
The file system is required to persist the data, So whenever you create a cluster in Databricks, it comes preinstalled with Databricks File System or DBFS.
The crucial detail to note is that DBFS is just an abstraction layer, and it practices Azure Blob storage at the back end to persevere the data.
So if users are working with some files, they can store the files in DBFS and Those files will actually be persisted in Azure Storage.
Using this, the files are also cached in the cluster, So even after the cluster is terminated, all the data is safe in Azure Storage.
One Azure Storage account that you see here is mounted to DBFS by default, but you can also mount multiple other Storage accounts like Azure Storage and Azure Data Lake Store.
2. Databricks Runtime
The second layer is the Databricks Runtime is a combination of several services like apache-spark, DBIO, Serverless clusters, Delta Lake, ML Framework, etc.
Apache Spark
Whenever you are creating a cluster, you select a Data bricks Runtime version, Each Runtime version comes bundled with a specific version of Apache Spark, and some additional set of optimizations over Spark.
In Azure, Databricks runs on Ubuntu OS, so Runtime comes with system libraries of Ubuntu.
Microsoft Azure
All the languages with their corresponding libraries are preinstalled, If you are interested to do machine learning, it preinstalls machine learning libraries.
And if you provision GPU-enabled clusters, GPU libraries are installed, Good thing is that versions of these libraries that are installed with Runtime work well with each other, preventing the trouble of manual configuration and compatibility issues.
In Databricks, you can create multiple clusters, and each cluster runs on a specific Spark version.
Azure Databricks
This implies you can run the same code on different versions of Spark, delivering it more natural to upgrade or test the performance.
Databricks I/O ( DBIO)
The Databricks I/O in short DBIO is a module that produces a distinct level of optimizations on Spark this can be related to caching, file decoding, disk read/write, etc.
The key thought to understand is the workload operating on Databricks can be delivered 10x times faster than standalone Spark deployments.
You can build multiple clusters in Databricks, and by paying more cost you can maximize the usage of the clusters.
Databricks Serverless Clusters
It is also called a high concurrency cluster, which has got an automatically managed shared pool of resources that enables multiple users and workloads to use it simultaneously.
But you might think, what if a large workload like ETL consumes a lot of resources and block the short and interactive queries by other users? Valid question.
That is the reason each user in a serverless cluster takes a fair part of resources, complete isolation, and security from other processes without making any manual configuration or tuning in the process.
This increases cluster utilization and gives another 10x performance improvement across primary Spark deployments.
To handle Databricks Serverless, you will possess to build a high concurrency cluster rather than a standard one.
Databricks ML Framework
Databricks also grant native support for different machine learning frameworks via the Databricks Runtime ML framework.
Databricks ML framework is created on Databricks Runtime for smooth machine learning work and for that every time you need to select Databricks Runtime ML at the time of creating the cluster.
The Databricks cluster always gives preinstalled libraries like Keras, GraphFrames, TensorFlow, PyTorch, etc.
Databricks also maintains third-party packages that you can install on the cluster, like scikit-learn, XGBoost, DataRobot, etc.
Delta Lake
In Databricks the very essential element is Delta Lake, It is made by the Databricks team called Databricks Delta, which made it open source for the world called Delta Lake.
Even though many teams move to Data Lakes, they struggle to manage them as the files in our Data Lake are still files, and they do not have the great features of relational tables.
This is where Delta Lake comes into the picture because Delta Lake is an open-source storage layer.
It brings features to Data Lake, which are very close to relational databases and tables and it gives ACID transaction support.
ACID support helps multiple users to work with the same files and get the ACID operation for better relational database operation.
Schema enforcement for the files, You can perform full DML operations like insert, update, delete, and merge. And using time travel, you can keep snapshots of data enabling audits and rollbacks, etc.
3. Databricks Workspace.
This is the last layer in Databricks with spark architecture that includes two parts, The first one is an interactive workspace and the second one is Production.
Interactive workspace
In this environment, you can investigate and analyze the data interactively see the results immediately similar to excel functionality.
In the same way, you can do complex calculations and interactively see the results in the workspace and You can also render and visualize the data in the form of charts.
In Databricks Workspace, you get a collaborative environment where various people can write code in an identical notebook, track the modifications of code, and push them to source control after completion.
Similarly, the datasets that you have processed can be put together on a dashboard, It could be for the end-users, or these dashboards can also be used to monitor the system.
Databricks Production
After you are done exploring the data, you can now build end-to-end workflows by orchestrating the notebooks.
These workflows you can easily deploy as Spark jobs and you can schedule using the job scheduler also.
Also, you can monitor these jobs, check the logs, and set up alerts, So in the same workspace, you cannot just interactively explore the data, you can also take it to production with minimal effort.
Conclusion
It brings together data engineering and data science workloads so that you can instantly start building your ETL pipelines, handle streaming data, perform machine learning, etc.
Similarly, it has an interactive environment for building solutions, sharing it with colleagues, and taking them to production, taking the game of data processing to a whole new level.
Databricks with spark architecture has several functionalities that can solve different level of problems while dealing with a large amount of data.
Recommended Articles:
Top 10 Benefits of Cloud Computing.
What is Virtual Network Peering in Azure?
What Is Databricks? – Components, Features, Architecture

Presenting the Data Engineer Team, a dedicated group of IT professionals who serve as valuable contributors to analyticslearn.com as authors. Comprising skilled data engineers, this team consists of adept technical writers specializing in various data engineering tools and technologies. Their collective mission is to foster a more skillful community for Data Engineers and learners alike. Join us as we delve into insightful content curated by this proficient team, aimed at enriching your knowledge and expertise in the realm of data engineering.








